一、背景概述
针对网站的Web攻击是互联网安全面临的主要威胁,为隐藏身份、逃避追踪,在对目标网站发起攻击时,黑客往往会采用多种手段隐藏自己的身份,如:使用(动态)代理、虚拟专用网络等。攻击者的这些手段很好的隐藏了自身信息,增加了安全人员追踪溯源的难度。
虽然针对Web攻击的防御技术、溯源技术也在不断发展之中,如: IDS、WAF、基于日志/流量溯源等,但这些技术往往处于被动防御的状态、或溯源信息不足,难以应对复杂多变的攻击手段。
- 问题一:攻击流量被隐藏在大量的合法流量中,不易被发现和识别。尽管IDS、WAF功能强大,但依然存在漏报或误报的可能,而且也存在因其自身漏洞或规则不完善而被绕过的可能。
- 问题二:即使识别攻击后,可基于IP黑名单机制阻断攻击源,但如果攻击者切换了出口IP,如何在新的攻击发起之前有效识别攻击行为,也是目前IDS、WAF等安全产品所不具备的功能。
- 问题三:假如攻击者在攻击过程中使用了(动态)代理、虚拟专用网络等手段,则传统的基于Web日志、基于网络流量的追踪技术,并不能有效的定位攻击者的身份或位置。
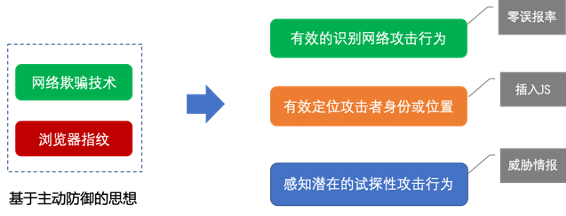
图1 研究目标
为弥补传统安全防御技术的不足,为网络犯罪溯源取证提供依据,基于主动防御的思想,本文提出了一种基于网络欺骗和浏览器指纹的溯源技术方案,旨在有效识别网络攻击行为、定位攻击者身份或位置,并可通过不同网站之间的协作或信息共享机制感知潜在的试探性攻击行为。
三、相关技术
1. 浏览器指纹技术

图2 浏览器指纹技术概述
在浏览器与网站服务器交互时,浏览器会向网站暴露许多的不同消息,比如浏览器型号、浏览器版本、操作系统等信息。如同人的指纹可以用来识别不同的人一样,当浏览器暴露信息的熵足够高时,网站就可利用这些信息来识别、追踪和定位用户。
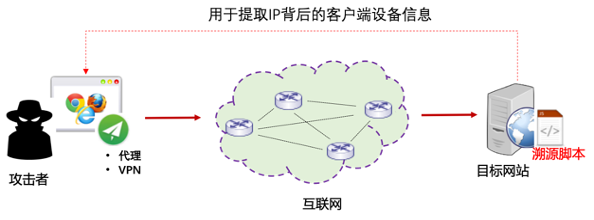

图3 浏览器指纹技术能力
将该技术应用于攻击溯源,即使黑客使用了(动态)代理、虚拟专用网络等,采集指纹信息的“溯源脚本”也可反向到达客户端的浏览器,进而被触发执行,以获取与黑客关联性更强的信息。其中,可采集的信息不仅包括客户端的系统字体、系统语言、浏览器插件、时区偏移量、Canvas、内外网IP等设备信息,也可采集攻击者的键盘记录、访问过的网站,甚至特定网站账号(存在JSONP漏洞)等行为信息。(“溯源脚本”基于JavaScript代码实现)
2. 网络欺骗技术
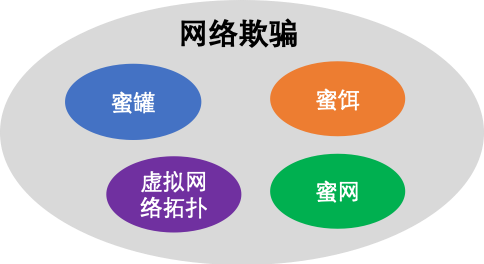
图4 网络欺骗技术概述
网络欺骗是一种针对网络攻击的防御手段(或策略),目的是让攻击者相信目标系统存在有价值的、可利用的安全弱点(伪造或不重要的),从而将攻击者引向这些错误的资源,以达到检测攻击、阻碍攻击、记录攻击行为的目的。其中,蜜罐是我们常见的一种网络欺骗技术,除了蜜罐技术,还存在蜜饵、蜜网、虚拟网络拓扑等多种欺骗技术实现方式。
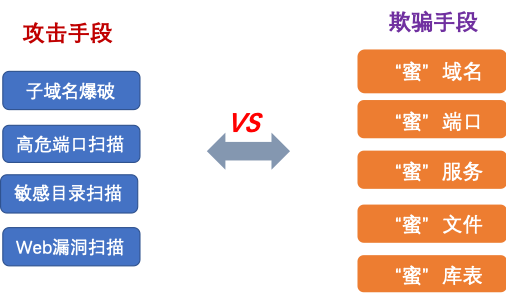
图5 网络欺骗技术手段
通常情况下,攻击者在试图攻击网站之前,都会有一些固有手法,用于收集目标网站的信息,如:子域名爆破,高危端口扫描、敏感目录扫描、Web漏洞扫描等。针对不同的攻击手段,可采用不同的欺骗手段来迷惑攻击者,如:针对子域名爆破行为,可部署虚假的网站并绑定子域名;针对目录扫描行为,可部署虚假的后台登录页面等。
四、应用场景
1. 应用场景-专用欺骗环境
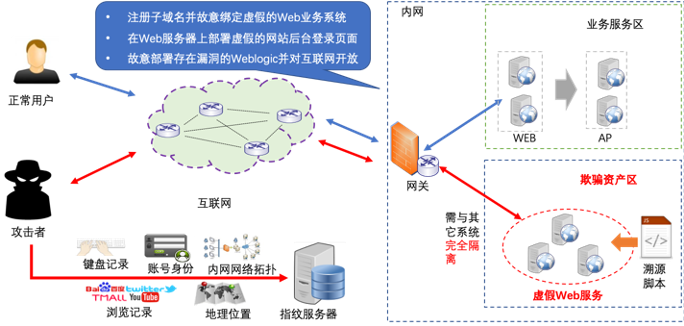
图6 专用欺骗环境架构
部署专用的网络欺骗环境,如:注册子域名并故意绑定虚假的Web业务系统;在Web服务器上部署虚假的网站登录、注册页面(用于抓取攻击者的手机号、邮箱等信息);部署存在漏洞的Weblogic并对互联网开放等。同时,所有的“欺骗性信息或服务”均不对外发布,只有采取一定的技术手段才能访问,而正常用户通常不会进行该操作。
2. 应用场景-常规网站防护
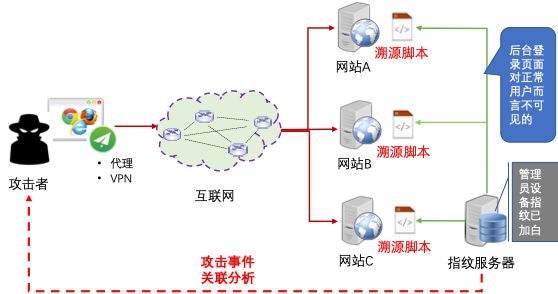
图7 网站后台防护架构
在真实的业务系统的管理员登录页面部署“溯源脚本”,不仅可采集攻击者的指纹信息,而且当某攻击者使用同一设备对多个业务系统的管理员登录页面实施攻击时,也可通过浏览器指纹将攻击事件进行关联。(备注:管理员设备的指纹信息已加白)
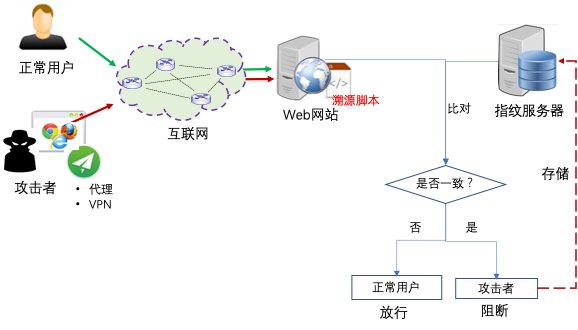
图8 网站整体防护架构
此外,也可在网站首页部署“溯源脚本”,采集所有用户的指纹信息,并与指纹库中(仅存储归属于攻击行为的客户端指纹)的信息做比较,以感知潜在的试探性攻击行为。该应用场景的优点在于,在攻击者对网站进行分析、查找漏洞的过程中,即可将其从大量正常流量中识别出来。
3. 应用场景-注入WebShell
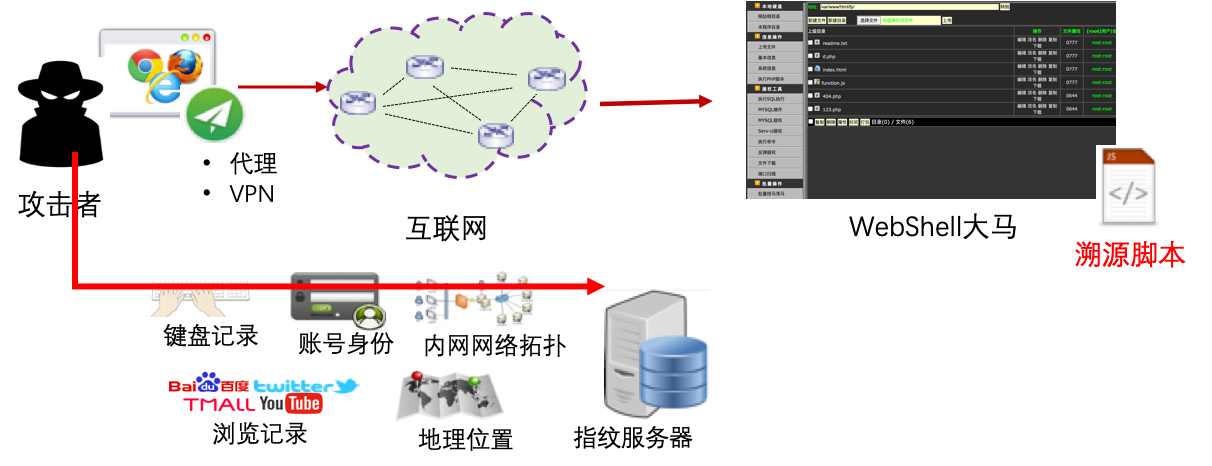
图9 溯源Webshell
当发现网站被攻击者入侵且留下WebShell后门时,除做好网络和机器隔离外,可暂时不清除木马文件,而是向其中插入“溯源脚本“, 等待攻击者再次访问,从而获取与攻击者关联性较强的指纹信息,为溯源取证提供依据。
五、优点与不足
1. 该方案的优点:
(1) 不存在误报
构建的欺骗环境不对互联网发布,正常用户是不可见的,只有采用一定手段才可能发现。凡是访问这些虚假资源的行为,均被认为是潜在的攻击行为,故不存在误报情况。
因此,相对于IDS、WAF等常规安全防护产品,基于网络欺骗技术,可将攻击流量从大量的合法流量中识别出来,不存在误报情况的发生。
(2) 改善漏报率
即使黑客在攻击过程中,使用了大量的代理服务器,不断的变化着出口IP地址。基于浏览器指纹技术,可及时发现采用同一设备发起的试探性攻击行为,进而阻断该攻击。(备注:实际使用时需考虑浏览器指纹的碰撞率问题)
因此,相对基于IP黑名单的防御机制,基于设备指纹的黑名单机制,可更快的感知、追踪和阻止攻击(即使攻击者使用了大量代理服务器),从而降低漏报情况的发生。
(3) 增强溯源能力
相对仅依靠服务端获取信息的溯源能力,基于浏览器指纹技术,可以采集与攻击者关联性更强的客户端信息,甚至其社交平台的账号(需要一定的前提条件),从而增强溯源取证的能力。
2. 该方案的不足:
(1) 指纹碰撞、指纹关联问题
首先,采集的不同客户端之间的指纹信息,存在指纹碰撞的情况,即: 不同设备的指纹被认为是同一设备。同时,也存在同一设备因切换网络环境、更新浏览器、或切换浏览器导致指纹信息不一致的情况。
因此,如何采集区别性更好的客户端特征属性以降低碰撞率、如果实现跨浏览器、跨设备的指纹追踪,是实际应用中需要考虑的问题。