
爬虫原理我是爬虫,每天穿越互联网,爬行我需要的一切。
谢谢你HTTP协议,因为它,世界各地的网站和浏览器都可以连接到通信,我也使用它HTTP协议,获取我想要的数据。
我只需要伪装成浏览器,发送到服务器HTTP你可以通过请求获得网页HTML文件。
然后,我再按HTML格式规范,分析图片、链接,表单
等待我关注的信息。

在获得链接标签后,我可以进一步爬上链接背后的网页,所以重复,不久,我就可以爬上网站暴露的内容。
当然,我们做爬虫还是有底线的。做我们这一行,有一个俗成的规定,那就是Robots协议。
只要你把一个名字放在网站的根目录下robots.txt禁止访问哪些目录的文件,我会绕道而行,就像这样:
搜索引擎位是搜索引擎的爬虫。他们爬得很高,爬得很光明。欢迎每个网站已经太晚了。他们都想被收录在搜索引擎中,给网站带来流量。这些爬虫都是圈子里的老板,我们惹不起。
还有一些爬虫,有些不遵守robots协议,随意爬,有的天天知道爬美图,爬别人的服务器崩溃,我们也看不起这些爬虫。
像我这样诚实的爬虫,日常工作就是爬一些网站的数据,比如购物网站、评论网站等等。虽然我们遵守规则,但这些网站仍然不喜欢我们。为了获取数据,我们展开了旷日持久的拔河战。
反爬虫技术
现在很多网站都在云上,云上的资源可以贵,CPU、内存、存储这些都价格不菲,尤其是网络带宽,价格是真心贵。
这些网站不喜欢我们这些爬虫可以理解,我们不喜欢搜索引擎爬虫可以给他们带来好处,相反,也会消耗他们的服务器性能,消耗他们宝贵的流量,但白人民币,谁不爱啊?
所以这些网站增加了一个措施:一旦HTTP请求中的user-agent如果字段发现是爬虫,就不理我们。
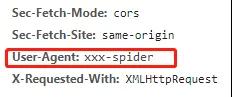
这个user-agent是HTTP协议中表示客户名字的字段,当时我刚进入这个行业,没有经验,不知道如何伪装,很容易被发现。
为了继续爬数据,我不得不改头换面,伪装成浏览器的名字。圈子里的一些兄弟也伪装成搜索引擎爬虫的名字。我没有像他们那样离线。
不久之后,这些网站升级了策略,通过我们的行为来确定它们是否是真正的浏览器。毕竟,我们是一个程序,比人类点击要快得多。一旦网站发现我们在短时间内发起了很多请求,它就会切断连接。
我不得不降低爬行频率,以免被列入黑名单。
有些网站更无情,在网页上插入一些假图片,只有几个像素,人类的眼睛看不见,但我们不知道啊,对我来说是标签,我一访问就中计了!立即被列入黑名单。
没别无选择,只能想办法改变这种事情。IP再爬一次,真是难顶。
听说圈子里有些大佬用分布式技术,组团爬,很多IP地址,其中一个或几个封了也不用怕,我真羡慕。
前后端分离
在我的职业生涯中,我遇到了一些奇怪的网站,显然网页上有数据,但我访问了它们HTML什么都没有,曾经让我很郁闷。
后来才知道,他们使用了一种叫做前后分离开发的技术,数据不再从服务器渲染到HTML在网页中,浏览器通过单独使用API接口拿到后动态加载。难怪我只得到一个空壳。
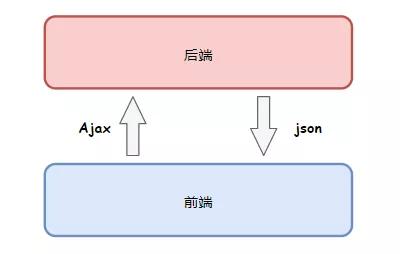
为了获取数据,我不得不学会要求这些数据接口,但因为这些网站都有API网关,会检查求Token或者Authorization这样的认证字段,加上我不知道他们的接口参数格式,我经常得不到数据。
在过去的两年里,我得到了网页HTML越来越简单,浏览器中丰富多彩的页面,一查源代码竟然只有几行简单,真是见鬼!
终于有一天,一位前辈告诉我,单页应用现在很流行SPA页面都是在前端动态生成的,得到的HTML毫无价值。
太欺人了!
我决定得到一个真正的浏览器。这个嵌入式浏览器没有界面,专门为我服务,嵌入到我的程序中,让他真正渲染网页。渲染完成后,我会取数据!
这是对人类访问网站的真实模拟,不再需要模拟繁琐的数据接口访问,也不用担心单页应用程序,前端渲染是前端渲染,我不再害怕!
验证码
后来不知道是谁发明的,网站们用了一种叫验证码的技术,给我们带来了问题。
最初的验证码相对简单,通常是一些简单的数字,英文字符做了一些变形,如此:
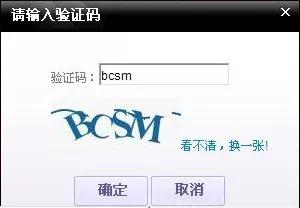
圈子里很快就有老板教我们用文字识别技术OCR来自动识别这个验证码,我也折腾了一下,花了很大力气终于能识别出来,准确率不敢说100%,99%还是有的。
然而,没过多久,验证码就变得越来越复杂。汉字识别、物体识别和滑动解锁越来越困难,这根本超出了我的理解范围。看看下面的验证码。这是人们做的吗?
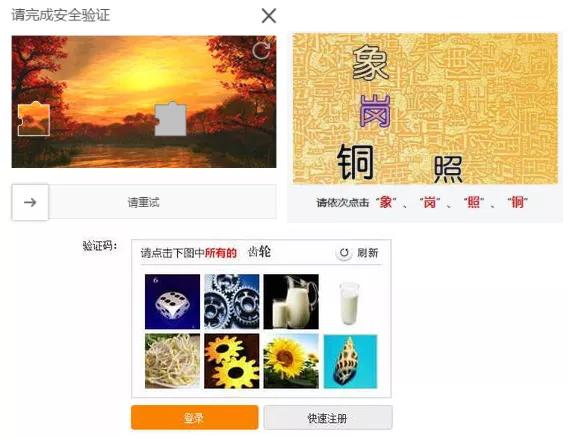
啊,这真的是人才能做的,不是我们爬虫能做的~
如今,这些网站的反爬虫技术越来越先进,我们可以一步一步地发挥空间。
前段时间,有个愣头青爬虫把一家公司的服务器给爬崩溃了,把人家正常业务都弄停掉了,他还被抓了起来,现在监管越来越严,搞得大家人心惶惶。
内忧外患不断,很多爬虫兄弟失业,转行,爬虫这碗饭,真的越来越不好吃了。