
本文转载自微信公众号「虞大胆的叽叽喳喳」,作者 虞大胆 。转载本文请联系虞大胆的叽叽喳喳公众号。
什么是指标
传统监控系统认为指标是附属物,但指标实际上用来反映环境的状态、可用性、性能。
指标是软件或硬件组件属性度量,为了让指标有价值,我们会跟踪其状态,通常就是记录一段时间内的数据点,数据点包含值、时间戳、其他一些属性,数据点的集合就是时间序列。
以固定时间(颗粒度)间隔收集数据,颗粒度越大就容易错过细节,时间序列是这些数据点按时间顺序排列的集合。
1:指标类型
- 测量型,这种类型是上下增减的数字,比如CPU负载。
- 计数型,这种类型随着时间增加而不会减少的数字,比如uptime运行时间。
- 直方图,数据分组,比如某个桶中的数值大小。
指标有的时候需要经过一些数学转换,通常指标聚合在一起才有意义,更能识别趋势,比如单台web流量下降的趋势比不上所有web流量的下降幅度。
(1)平均值
平均值不能反映真实情况,比如高峰和低谷会被平均值掩盖。
(2)中间数
中间数处在所有数值的正中心,50%的数值位于它前面,而另外50%位于它后面。它的缺点和平均值一样,不能反映真实情况。
(3)标准差
用于衡量数据集的变化或分布,标准差为0表示大部分数据接近平均值,标准差越大表示数据越分散。
正态分布也称之为经验法则,但如果数据不是正态分布,最终的标准差可能会误导你。
(4)百分数
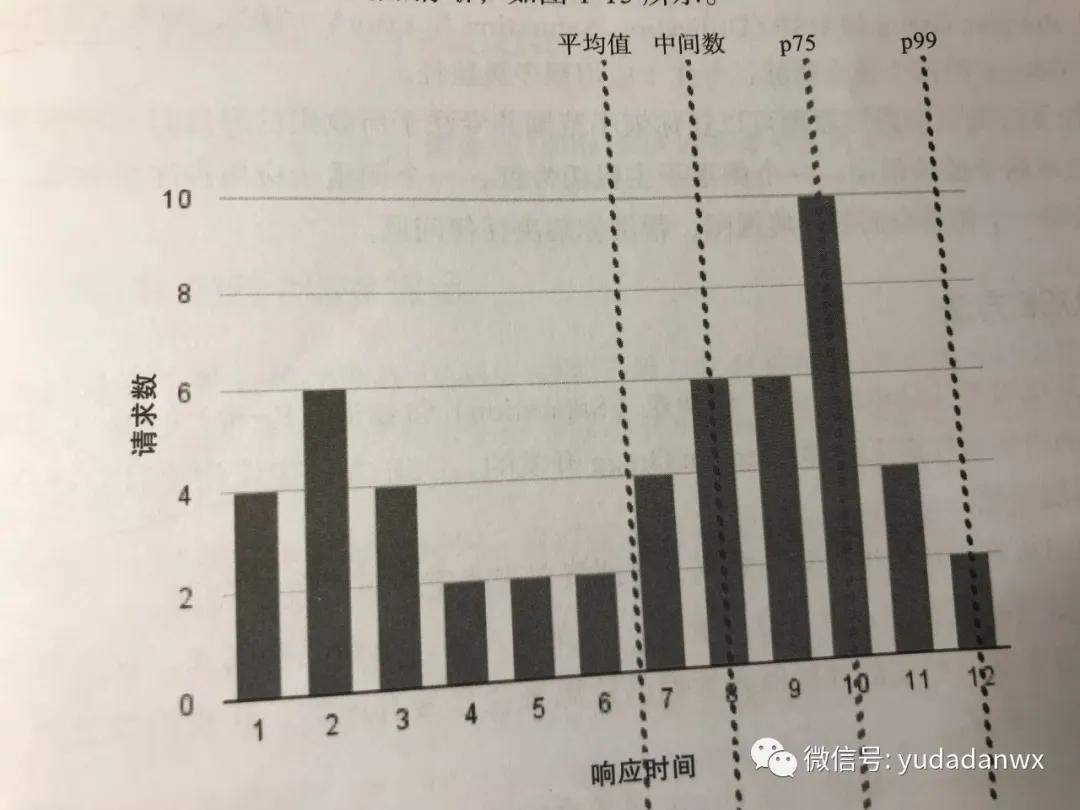
这个最有意义,比如99% API响应时间小于100毫秒,代表整体性能不错,而我们要解决的就是剩余的1%。
监控方法论
1:USE:侧重于主机监控
概括为每个资源(比如CPU),检查使用率(资源忙于工作的平均时间,一般是百分比)、饱和度(资源排队工作的指标,无法再处理额外的工作,通用用队列长度表示)、错误(资源错误时间的计数)。
2:Google四个黄金指标
专注于应用程序级的监控。
- 延迟,服务请求花费的时间
- 流量,比如QPS
- 错误,请求失败的速率
- 饱和度,应用程序受限的资源(比如IO)
警报和通知
警报在达到阈值时会触发,但触发不代表通知,所以这是两个过程。
警报在于准确,否则就没有意义了,同时报警信息也要有上下文(此时知道应该干些什么了),考虑:
- 那些问题需要通知
- 谁需要被告之
- 如何告之
- 多久告之一次
- 何时停止告之以及何时升级到其他人
数据可视化是一门非常强大的分析和解释技术,也是一种牛逼的学习工具。
- 清晰地显示数据
- 引发思考
- 避免数据扭曲
- 使数据集保持一致
- 允许更改颗粒度而不影响理解